Sponsored
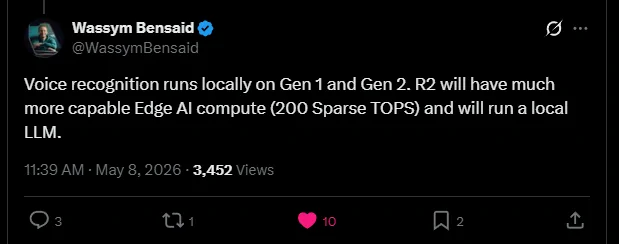
Confirmed: Voice recognition local processing for R1 (Gen 1 and Gen 2). The R2 will have a local LLM.
kanundrum
Well-Known Member
- Joined
- May 2, 2020
- Threads
- 273
- Messages
- 4,685
- Reaction score
- 13,660
- Location
- Washington, DC
- Vehicles
- Giulia QV, R1S (Sept 22 Delivery)
- Occupation
- IT
I don't get how this will let bub rub go woooooo woooooooo but here we are
LivingInKaos
Well-Known Member
That's odd given just last week they said Gen 1 was completely cloud based. So many conflicting messages from Rivian and it's getting worse every day. Just like the crossbars on R2, I would take everything that comes out of their mouths with a grain of salt until it actually happens.
Sponsored
Mellowyellow
Well-Known Member
Is this from the get go? The next update will include this? Or is this one of the features coming soon?
DuoRivian
Well-Known Member
- Joined
- Sep 3, 2023
- Threads
- 3
- Messages
- 1,592
- Reaction score
- 1,753
- Location
- California
- Vehicles
- Rivian R1T and an R1S
- Occupation
- IT
The RAP1 chip is for autonomy ONLY. The rest of the compute will stay the same as we go into 2027 including the infotainment. So this is not a reason to delay purchase until mid 2027.For local LLM; I wonder if he’s referring to all R2 or just the Gen3 (RAP1) versions of the R2.
CharonPDX
Well-Known Member
Basic voice recognition for baked commands requires ridiculously little processing power. My computer in 1999 could do it. Cars in the mid '00s could do it.That's odd given just last week they said Gen 1 was completely cloud based. So many conflicting messages from Rivian and it's getting worse every day. Just like the crossbars on R2, I would take everything that comes out of their mouths with a grain of salt until it actually happens.
No, you won't get LLMs, you probably won't even get "complex commands." But "lower temperature to 69 degrees" won't be a problem. "Open tonneau" shouldn't be a problem. (Although my 2016 Tesla Model S with MCU2 still can't do simple things like "open the sun roof", that's on Tesla for not programming in the basic commands.)
usulio
Well-Known Member
The fun part: when Rivian tries to do all this through a complex LLM setup that ends up performing worse and less predictably than old tech (for way more money).Basic voice recognition for baked commands requires ridiculously little processing power. My computer in 1999 could do it. Cars in the mid '00s could do it.
No, you won't get LLMs, you probably won't even get "complex commands." But "lower temperature to 69 degrees" won't be a problem. "Open tonneau" shouldn't be a problem. (Although my 2016 Tesla Model S with MCU2 still can't do simple things like "open the sun roof", that's on Tesla for not programming in the basic commands.)
portdirect
Well-Known Member
“Local LLM” does not mean much beyond marketing unless the implementation details are clear.This was posted by Wassym regarding voice recognition local processing.

“200 sparse TOPS” raises more questions than it answers. At what precision? BF16, INT8, INT4? What sparsity format? Does the runtime actually use it? Most normal LLMs are dense, and I am not talking about MoE versus dense model architecture. I mean whether the model weights and kernels can actually exploit hardware sparse acceleration.
Memory capacity and bandwidth are likely the real limiting factors. I could see a 3B to 4B model running well on an updated infotainment system, and maybe a 7B to 8B model if the memory system is fast enough.
But even that is secondary. The useful question is what they intend to do with it. The harness, modality, latency target, tool access, context strategy, and product integration matter more than the TOPS number.
Sponsored
godfodder0901
Well-Known Member
- First Name
- Jared
- Joined
- Mar 12, 2019
- Threads
- 27
- Messages
- 5,748
- Reaction score
- 10,138
- Location
- Washington
- Vehicles
- 2022 Rivian R1T LE
INT8.“Local LLM” does not mean much beyond marketing unless the implementation details are clear.
“200 sparse TOPS” raises more questions than it answers. At what precision? BF16, INT8, INT4? What sparsity format? Does the runtime actually use it? Most normal LLMs are dense, and I am not talking about MoE versus dense model architecture. I mean whether the model weights and kernels can actually exploit hardware sparse acceleration.
Memory capacity and bandwidth are likely the real limiting factors. I could see a 3B to 4B model running well on an updated infotainment system, and maybe a 7B to 8B model if the memory system is fast enough.
But even that is secondary. The useful question is what they intend to do with it. The harness, modality, latency target, tool access, context strategy, and product integration matter more than the TOPS number.
portdirect
Well-Known Member
where did you find that? I’ve only seen some stuff for RAP1 - not the updated infotainment system.INT8.
godfodder0901
Well-Known Member
- First Name
- Jared
- Joined
- Mar 12, 2019
- Threads
- 27
- Messages
- 5,748
- Reaction score
- 10,138
- Location
- Washington
- Vehicles
- 2022 Rivian R1T LE
Because there isn't any mention of the new infotainment. The 200 tops was per RAP1.where did you find that? I’ve only seen some stuff for RAP1 - not the updated infotainment system.
Rade
Well-Known Member
- First Name
- Rade
- Joined
- Sep 19, 2024
- Threads
- 36
- Messages
- 601
- Reaction score
- 768
- Location
- US - Rhode Island
- Website
- radmorningcoffee.blogspot.com
- Vehicles
- 2025 Rivian R1T - Large. Delivered on November 23, 2024.
- Occupation
- Retired
FWIW; we have gotten used to using the Grok AI assistant in the Model Y. Nice to keep eyes on the road and ask it to route to a destination. Will look forward to a similar function in my Gen 2 R1T.
portdirect
Well-Known Member
I think you’re conflating two separate Rivian claims.Because there isn't any mention of the new infotainment. The 200 tops was per RAP1.
Rivian’s R2 media material places the 200 sparse TOPS figure under the R2 infotainment compute module. RAP1 is described separately as part of the Gen 3 Autonomy Computer, which Rivian rates at 1600 sparse INT8 TOPS (using a pair of RAP1 modules).
200 sparse TOPS under typical 2:4 sparsity, is roughly 100 dense TOPS. That puts it closer to modern high-end smartphone SoC territory than an autonomy-class accelerator.
That is still good hardware for an infotainment system. I just think Rivian’s AI marketing would be clearer (and of course they know this too, and are clearly intentionally being ambiguous) if they stated the dense-equivalent performance, precision, memory, etc. Considering the last information SOC was mediatek (if I recall correctly) then this could simply be that they moved from that, the CV5 and another pair of supporting SOCs (WiFi and GPS?) to something like https://www.mediatek.com/products/smartphones/mediatek-dimensity-9500 and are just going full AI,AI,AI,AI on how they describe this.
Sponsored
Last edited:
Similar threads
- Replies
- 122
- Views
- 13,311
- Replies
- 144
- Views
- 14,668
- Replies
- 2
- Views
- 863

- Replies
- 22
- Views
- 1,343